자연어란?
- 한국어, 영어 등 우리가 평소에 쓰는 말
자연어처리(Natural Language Processing, NLP)란?
- 자연어를 처리하는 분야
- 우리의 말을 컴퓨에게 이해시키기 위한 기술(분야)
단어는 의미의 최소 단위라고 할 수 있음
자연어를 컴퓨터에게 이해시킬 때 '단어의 의미'를 이해시키는 게 중요!
즉, 단어의 의미를 잘 파악할 수 있는 표현 방법에 대해 고민해봐야 한다
딥러닝 이전의 고전적인 방법들은 크게 3가지가 있다.
1. 시소러스를 활용한 기법
2. 통계 기반 기법
3. 추론 기반 기법(ex. word2vec)
시소러스
- 시소러스 형태의 사전을 초창기에는 이용했음
- 동의어 그룹, 유의어 그룹
- 상위와 하위, 전체와 부분 등 세세한 관계를 그래프 구조로 정의
- NLP 분야의 가장 유명한 시소러스 WordNet


즉, 시소러스란 수많은 단어에 대한 동의어,유의어, 계층 구조 등의 관계가 정의되어 있는 사전
이 지식을 활용하면 단어의 의미를 간접적으로라도 컴퓨터에 전달할 수 있음
시소러스의 문제점
- 비용 문제 -> 수작업으로 시소러스 사전을 구축해야함
- 시대 변화에 대응 어려움 -> 수작업으로 바꿔줘야하기 때문
- 단어의 미묘한 차이를 표현하기 어려움 -> 수작업이라서 세세하게 표현하기 힘듦
통계 기반 기법
- 코퍼스(말뭉치)에는 사람의 지식(문장을 쓰는 법, 단어를 선택하는 법, 단어의 의미 등)이 담겨 있음.
- 통계 기반 기법의 목표는 코퍼스에서 자동으로, 효율적으로 핵심을 추출하는 것
단어의 표현 방법
통계 기반 방법이 무엇인지 알아보기 전에 단어의 표현 방법은 크게 2가지로 나눌 수 있다.
1. 국소 표현(Local Representation)
- 해당 단어 그 자체만 보고, 특정값을 맵핑하여 단어를 표현하는 방법
- puppy, cute lovely라는 단어가 있을 때 각 단어에 1번, 2번, 3번 등과 같은 숫자를 맵핑
2. 분산 표현(Distributed Representation)
- 그 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법
- puppy라는 단어 근처에는 주로 cute, lovely라는 단어가 자주 등장 -> puppy는 cute, lovely한 느낌이다로 단어를 정의
국소 표현은 단어의 의미, 뉘앙스를 표현할 수 없지만, 분산 표현은 단어의 뉘앙스를 표현할 수 있게 됨
-> 분산 표현을 통해 단어의 의미를 파악할 수 있는 벡터로 표현
분포 가설(Distributional Hypothesis)
- "단어의 의미는 주변 단어에 의해 형성된다"
- 단어 자체에 의미는 없고, 그 단어 사용된 맥락이 의미를 형성함
통계 기반 기법이란?
- 주변 단어의 빈도를 기초로 단어를 벡터로 표현하는 방법
- 분포 가설을 기반으로 분산 표현을 통해 단어를 벡터로 표현
- 주변 단어를 참고하는(분포 가설에 기반한) 가장 기초적인 방법은 주변 단어를 세어보는 것
-> 동시 발생 행렬
동시 발생 행렬 예시
Ex) you say goodbye and i say hello .


위 그림은 윈도우 크기를 1로 하고, you의 맥락 안에 포함되는 단어들의 빈도를 표로 나타낸 것이다.
이는 [0,1,0,0,0,0,0] 이렇게 벡터로 표현할 수 있다
맥락 안의 모든 단어에 대해 이 과정을 반복하면 아래 표와 같고, 이 표가 행렬을 띤다는 뜻에서 동시 발생 행렬이라고 한다
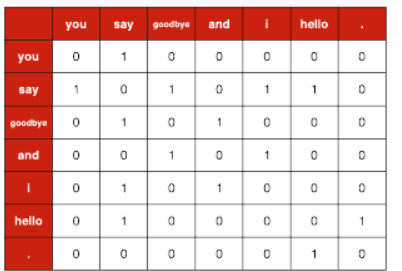
동시 발생 행렬을 통해 단어의 벡터 표현을 얻을 수 있게 됐다.
정확히 말하면 통계적 기반 기법을 활용하여 분포 가설을 기반으로 분산 표현을 통해 단어를 표현할 수 있게 됐다.
Ex) say라는 단어의 벡터는 [1,0,1,0,1,1,0] 이다.
통계 기반 기법 개선하기
1. PMI
통계 기반 기법은 빈도수에 기반하기 때문에 실제로는 의미가 없는 고빈도 단어와 강한 관련성을 갖는다고 평가된다
Ex) car 라는 단어는 drive와 관련이 더 있지만, 빈도수 기반으로 보면 the와의 관련성이 더 높음
이를 해결하기 위해, 점별 상호정보량(Pointwise Mutual Information, PMI) 이라는 척도를 도입
PMI 식은 아래 그림과 같다
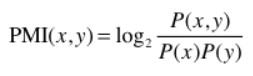
PMI 값이 높을수록 두 단어간의 관련성이 높다는 뜻
10,000개의 단어로 이루어진 말뭉치에서 the가 100 번 등장했다면, p('the')= 0.01
10,000개의 단어로 이루어진 말뭉치에서 the와 car가 동시에 10번 등장했다면, p('the', 'car') = 0.001
N을 말뭉치의 단어수, C(x)를 x의 등장횟수라고 한다면 아래의 식으로도 이해할 수 있다
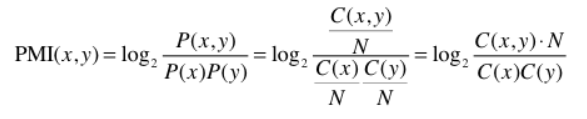
예시에서 언급한 경우를 계산하면 아래와 같은데,
car는 the 보다 drive와 더 관련이 높다는 걸 알 수 있다
이러한 결과가 나온 이유는 the가 단독으로 출현하는 횟수를 고려했기 때문, 즉, 고빈도 단어임을 고려했기 때문

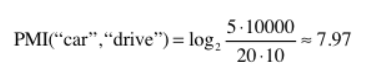
+ 추가적으로 두 단어의 동시발생 횟수가 0인 경우 PMI가 음의 무한대로 발산하기 때문에 아래와 같이 양의 상호 정보량(PPMI)를 도출할 수 있음

이렇게 도출한 PPMI를 통해 PPMI 행렬을 구축한다
PPMI 행렬은 동시 발생 행렬 보다 단어의 의미를 잘 표현한 벡터!
2. 차원 감소
희소 벡터를 밀집 벡터로 만들어주기 위해서 차원 축소를 한다. 단, 중요한 정보를 최대한 유지하면서 차원을 줄인다
공간의 낭비를 줄이기 위해 희소 벡터(원소 대부분이 0인 벡터)를 밀집 벡터로 만들어줌
밀집 벡터(조밀한 벡터)야 말로 단어 분산 표현이라고 할 수 있음
SVD
- 특잇값분해, 차원 축소 방법 중 하나
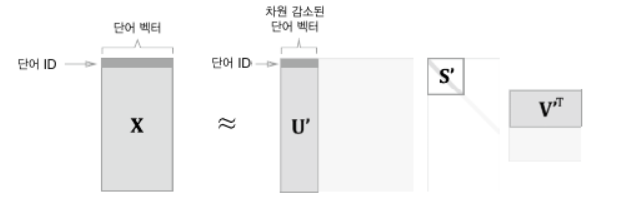
- 아래 그림 처럼 임의의 행렬 X를 세 행렬의 곱으로 분해

U와 V는 직교행렬, S는 대각행렬
U행렬 : 단어 공간
S행렬 : 대각성분에는 특잇값(해당 축의 중요도)이 큰 순서대로 나열되어 있음.
S행렬에서 특잇값이 낮다면 중요도가 낮다는 뜻
아래 그림처럼, U행렬에서 여분의 열 벡터를 깎아서 원래의 행렬을 근사할 수 있음
X의 각 행에는 단어 벡터가 있고, U 프라임 행렬의 각 행에는 차원 축소된 단어 벡터가 존재
정확히는 단어의 동시 발생 행렬 X는 정방행렬
'Python > NLP' 카테고리의 다른 글
| BERT 활용 - 질의 응답(Question Answering) (0) | 2023.08.09 |
|---|---|
| 트랜스포머(Transformer) - 인코더, 디코더 (0) | 2023.07.19 |
| 트랜스포머(Transformer) - 입력(포지셔널인코딩) (0) | 2023.07.15 |
| 어텐션(인코더-디코더 Attention, Dot-Product Attention) (0) | 2023.06.27 |
| 시퀀스-투-시퀀스(seq2seq) (0) | 2023.04.11 |



