https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
트랜스포머란?
- 인코더-디코더 구조를 따르면서, RNN을 사용하지 않고 어텐션으로만 구현한 모델
인코더-디코더 구조
- 인코더 : 입력 시퀀스를 하나의 벡터 표현으로 압축
- 디코더 : 압축된 벡터 표현을 통해서 출력 시퀀스 생성
-> 좋은 성능을 보이는 Neural sequence transduction model들은 대부분 이 구조
- memory와 computation 때문에 벡터의 max length를 제한해야됨
-> 입력 시퀀스의 정보가 압축 과정에서 손실됨
-> 이를 보정하기 위해 어텐션 구조 사용하는 등 여러가지 시도가 있었는데
그 중 가장 강력한 방법이 트랜스포머
"어텐션을 RNN의 보정을 위한 용도로 사용하는 것이 아니라,
어텐션만으로 인코더-디코더를 만들어보자"
트랜스포머 구조
- 인코더-디코더 구조
- 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점을 가지는 구조 "아님"
-> 순차적으로 입력을 받아서 처리하는 RNN의 특징이 트랜스포머에는 없음. 즉, 한 번에 입력받음
- 인코더와 디코더라는 단위가 N개로 구성 (논문에서는 6개)

인코더와 디코더가 여러개라는 의미로 s를 붙여서 아래 그림과 같이 표현할수 있음
I am a student 라는 문장이 시점별로 하나씩 들어오는 것이 아니라, 한 번에 입력됨

트랜스포머 입력 (포지셔널 인코딩)
RNN을 사용하지 않기 때문에 입력 시퀀스를 순차적으로 입력 받지 않음. 앞서 언급한 것 처럼 한 번에 입력 받음.
그래서 문제가 하나 생겼는데, 바로 입력 시퀀스의 위치 정보를 모른다는 것. 즉, 단어의 위치 정보를 모름
-> 포지셔널 인코딩 등장
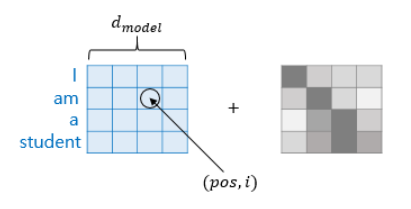
포지셔널 인코딩(positional encoding)
- 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보를 더해서 입력 값으로 사용
- 아래 그림처럼, 트랜스포머의 입력에 포지셔널 인코딩 값이 더해져서 입력 값으로 사용됨


포지셔널 인코딩에 대해서 자세히 이해해보자
포지셔널인코딩으로 선택할 수 있는 방식에는 어떤 것이 있을까?
두가지 정도의 방법을 생각해보면
1) 데이터에 0~1사이의 label을 붙이는 방법.
- 0이 첫번째 단어, 1이 마지막 단어
- I love you: I 0 /love 0.5/ you 1
한계
- Input의 총 크기를 알 수 없음, 즉 delta 값이 일정한 의미를 갖지 않음.(delta = 단어의 label 간 차이)
-> 문장이 길어진다면, 단어 간 라벨의 차이는 점점 줄어듦.
2) 각 time-step마다 선형적으로 숫자를 할당하는 방법. (delta일정해짐)
- 첫번째 단어 는 1, 두 번째 단어는 2
- I love you: I 1/ love 2/you 3
한계
- 숫자가 매우 커질 수 있음, 총 크기에 따라 가변적
- 학습할 때보다 큰 값이 입력값으로 들어오게 될 때 모델의 일반화가 어려워짐, 특정한 범위 값을 갖는게 아니라서
이러한 예시를 통해 이상적인 포지셔널 인코딩은 다음과 같은 기준을 충족시켜야 함을 알 수 있다!
1) 각 time-step(문장에서 단어의 위치)마다 하나의 유일한 encoding 값을 출력해 내야 한다.
2) 서로 다른 길이의 문장에 있어서 두 time-step 간 거리는 일정해야 한다.
3) 모델에 대한 일반화가 가능해야 한다. 더 긴 길이의 문장이 나왔을 때 적용될 수 있어야 한다. 즉, 순서를 나타내는 값 들이 특정 범위 내에 있어야 한다.
4) 하나의 key 값처럼 결정되어야 한다. 매번 다른 값이 나와선 안된다.
논문에서 트랜스포머 모델에서 사용된 encoding 기술은 위의 기준들을 모두 충족한다
-> 위치 정보를 가진 입력 값을 만들기 위해서 아래 두 개의 함수를 사용
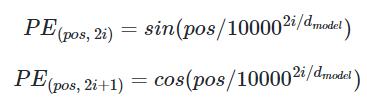
-> 이 두가지 함수의 값을 임베딩 벡터에 더해줌으로써 단어의 순서 정보를 반영함
ex) 같은 단어라고 하더라도 문장 내의 위치에 따라서 트랜스포머의 입력으로 들어가는 임베딩 벡터의 값이 달라짐
pos : 입력 시퀀스에서의 임베딩 벡터의 위치
i : 임베딩 벡터 내의 차원의 인덱스 -> 짝수인 경우에는 sin, 홀수인 경우에는 cos
d(model) : 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기, 임베딩 벡터의 차원(논문에서는 512)
포지셔널 인코딩 함수의 정의를 자세히 살펴보자
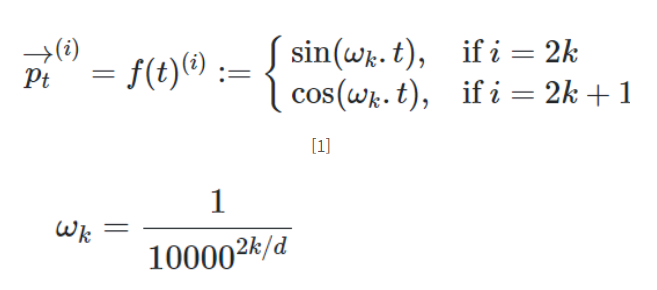
- p(t) 는 포지셔널 임베딩으로 들어가는 값
- 벡터의 차원 (d(model))에 따라, sin/cos의 주기가 길어짐
- 파장에서 2pie 에서 10000*2pie까지의 기하 수열을 보임
이게 무슨 말이냐면,
wk의 값이 0에 가까워질 수록 sin/cos의 주기가 길어지게됨.
벡터의 차원이 4라면,
wk는 1/10000^(0.25) , 1/10000^(0.5) , 1/10000^(0.75) , 1/10000 값을 갖게됨
wk가 1/10000 이라면, sin/cos함수의 주기는 10000*2pie
wk가 1/10000^(0.5) 라면 sin/cos함수의 주기는 100pie
wk가 1/10000^(0) 에 수렴한다면 sin/cos함수의 주기는 2pie
즉 파장이 2pie ~ 10000*2pie의 값을 갖게 되며
이러한 sin/cos함수로 순서값을 표현하게 된다!
아래는 포지셔널 인코딩을 수행할 때, 즉 입력값에 더해지게 되는 벡터이다.
t는 임베딩벡터의 차원 인덱스 별로 존재하는 값들이 차례로 들어갈 곳이라고 생각하면 된다.
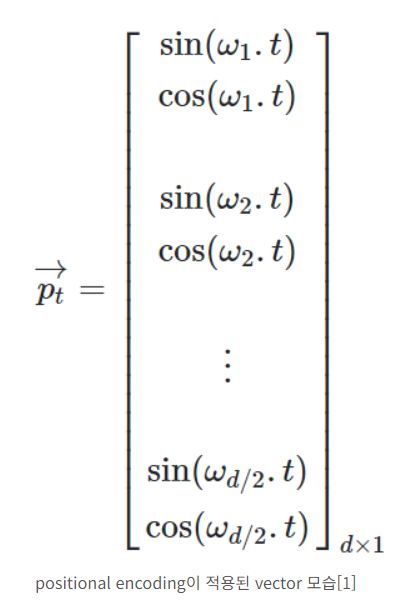
정의는 알겠는데 그래서 어떻게 sin,cos 조합으로 순서값을 표현할 수 있는걸까?
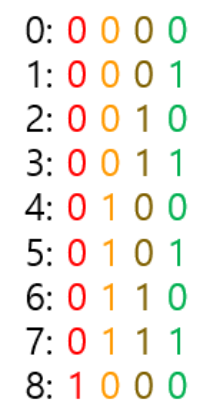
이진 bit를 통해서 이해해보자
가장 작은 bit, 즉 가장 오른쪽은 1이 증가할 때 마다 바뀌고
두번째로 작은 bit는 2가 증가할 때 마다 바뀐다
세번째로 작은 bit는 4가 증가할 때 마다 바뀐다
즉, n번째로 작은 bit는 2^(n-1)이 증가할 때 마다 바뀌는 것을 알 수 있다
이진 bit의 변화 규칙을 통해 숫자들 사이의 관계에 접근할 수 있다
sin/cos함수도 똑같다.
sin/cos함수의 값들의 변화 규칙을 통해 즉, sin/cos함수의 주기적인 패턴을 통해 서로 다른 위치에 대해 고유한 값을 생성하여 위치 정보를 반영하는 것이다.
사실 이러한 공식은 주로 경험적으로 발견된 것들이라고 하며,
포지셔널 인코딩에 대한 연구는 계속 진행 중이라고 한다.
주기적인 패턴을 통해 고유한 값을 생성할 수 있는 sin/cos함수의 특징을 통해 단어의 순서 정보를 반영한다!
라고 이해하면 될 것 같다
자세히 풀어보기
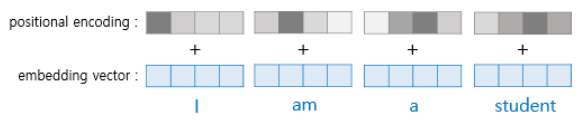
포지셔널 인코딩이 더해지는 모습을 표현하면 아래 그림과 같다
d(model)을 4로 가정한다면,
아래 그림과 같이 하나의 시퀀스 행렬과 포지셔널 인코딩 행렬의 덧셈을 통해서 순서 정보를 반영한다
임베딩 벡터 내의 차원 인덱스가 짝수인 경우에는 sin, 홀수인 경우에는 cos 함수를 사용한다
구체적으로 풀어서 적어보자면,
아래 예시에는 I 라는 단어의 4차원 임베딩 벡터가 존재한다
1번째, 3번째 인덱스에는 cos 함수가 적용되고, 2번째, 4번째 인덱스에는 sin 함수가 적용된다.
아래에 함수는 앞서 언급헀던 포지셔널 임베딩 과정에서 더해지는 값, 즉 위치 정보를 가진 값을 만드는 함수다.
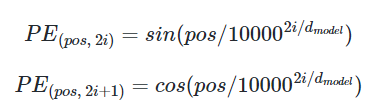
이를 토대로 각각의 값을 풀어서 적어보면, 다음과 같다
I의 임베딩 벡터의 1번째 인덱스 : cos(1/10000^(0.25))
I의 임베딩 벡터의 2번째 인덱스 : sin(1/10000^(0.5))
I의 임베딩 벡터의 3번째 인덱스 : cos(1/10000^(0.75))
I의 임베딩 벡터의 4번째 인덱스 : sin(1/10000)
이러한 값들이 I 뿐만 아니라 다른 단어들에도 더해짐으로써 단어의 순서 정보를 반영하게 된다
작성시 아래 글을 참고하였다
positional encoding이란 무엇인가
Transformer model을 살펴보면, positional encoding이 적용된다. 다음 그림은 transformer 모델에 대한 구조도 인데, positional encoding을 찾아볼 수 있다. 출처는 https://www.tensorflow.org/tutorials/text/transformer 이다. tra
skyjwoo.tistory.com
'Python > NLP' 카테고리의 다른 글
| BERT 활용 - 질의 응답(Question Answering) (0) | 2023.08.09 |
|---|---|
| 트랜스포머(Transformer) - 인코더, 디코더 (0) | 2023.07.19 |
| 어텐션(인코더-디코더 Attention, Dot-Product Attention) (0) | 2023.06.27 |
| 시퀀스-투-시퀀스(seq2seq) (0) | 2023.04.11 |
| 장단기 메모리(Long Short-Term Memory, LSTM) (0) | 2023.03.26 |



