시퀀스-투-시퀀스(seq2seq)
시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) - 입력된 시퀀스를 다른 시퀀스로 변환하는 작업을 수행하는 딥러닝 모델 - 주로 자연어 처리(NLP) 분야에서 활용 - ex) 챗봇, 기계 번역, 요약, STT 아래 그
tgwon.tistory.com
RNN에 기반한 seq2 seq 모델의 한계
- 컨텍스트 벡터로 정보 압축 과정에서 정보 손실 발생, 입력 시퀀스가 길어지면 심함
- RNN의 고질적인 문제인 기울기 소실 문제
-> 그래서 등장한 게 어텐션(attention)
-> 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정
어텐션 아이디어
디코더에서 출력 단어를 예측하는 매 시점마다, 인코더에서의 전체 입력 문장을 다시 한번 참고하자
단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 참고하자
어텐션 요약
- seq2seq attention(인코더-디코더 어텐션)
Q = Query : t 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
(Q,K,V를 뭐로 생각하느냐에 따라서 어텐션의 종류가 달라짐. 위 사례는 인코더-디코더 어텐션)
Attention(Q, K, V) = Attention Value
: 어텐션 함수, Q,K,V를 통해 어텐션 값을 도출함
1. 주어진 '쿼리(Q)'에 대해서 모든 '키(K)'와의 유사도를 각각 구함
2. 유사도를 키와 맵핑되어있는 각각의 '값(V)'에 반영
3. 유사도가 반영된 '값(V)'을 모두 더해서 리턴 -> 어텐션 값(Attention Value)
닷-프로덕트 어텐션(Dot-Product Attention)

- 어텐션의 다양한 종류 중 하나
-> seq2seq + 어텐션(닷-프로덕트) 인 상황
-> 인코더의 은닉 상태와 디코더의 은닉 상태의 차원이 같다고 가정
-> 디코더의 세번째 셀에서 출력 단어를 예측하는 상황
1. 어텐션 값 (Attention Value)
h(1), h(2),..., h(t) : 인코더의 은닉 상태(hidden state)
s(t) : 디코더의 t시점에서의 은닉 상태(hidden state)
디코더의 t시점에서 필요한 입력값은?
- h(t-1)
- t-1 시점에 예측되어서 나온 출력단어
어텐션 메커니즘에서 디코더의 t시점에서 필요한 입력값은?
- h(t-1)
- t-1 시점에 예측되어서 나온 출력단어
- 어텐션 값(Attention Value), a(t) : t번째 단어를 예측하기 위한 어텐션 값
어텐션 값은 디코더의 t시점에서의 예측에 영향을 줌
2. 어텐션 값 구하기

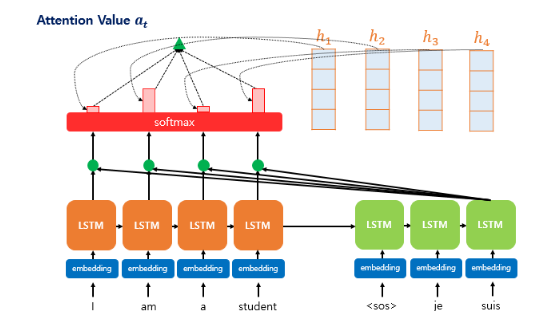
어텐션 스코어(Attention Score)
- 인코더의 모든 은닉 상태 각각(h(1),h(2),...,h(t))이 디코더의 t시점의 은닉 상태(s(t))와 얼마나 유사한지 판단하는 스코어값
- 아래 그림처럼 s(t)를 전치해서 각각의 은닉상태와 내적을 통해서 어텐션 스코어들을 산출함
-> 어텐션 스코어는 스칼라값

- e(t) : 어텐션 스코어들의 모음 값
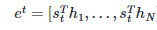
어텐션 스코어의 의미
- 유사도 스칼라
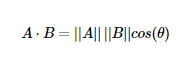
성분곱(dot product, 내적) 은 위 사진과 같이 정의된다.
그냥 대응되는 벡터의 성분들간의 곱이라고만 이해하기보다,
정의된 수식에 따르면 성분곱은 " 두 Vector의 방향과 크기까지 고려해서 유사도를 보는 것"
어텐션 스코어를 구할 때 들었던 의문점
-> 단순히 내적값이 유사함을 의미하는가?
ㅇㅇ 내적은 방향과 크기까지 고려한 유사도 척도. 단순히 성분들간의 곱이라고 이해하지말자
-> 내적은 벡터 길이가 같아야하는데, 다른 경우엔 어떻게 하는가?
??
- 아래에 참고했던 좋은 글에 대해서 출처를 남긴다
유사도Similarity와 거리들 - 여기에서 많은 것들이 시작된다. (tistory.com)
유사도Similarity와 거리들 - 여기에서 많은 것들이 시작된다.
이제까지는 최소값에 대한 이야기를 했다면, 데이터끼리 얼마나 가까운지(비슷한지)를 어떤 식으로 접근하는지도 들여다봐야 하겠습니다. 이 Similiarity를 잘 이해할 수 있다면 여러 가지 모형에
recipesds.tistory.com
어텐션 분포(Attention Distribution)
- e(t)(어텐션 스코어 모음)에 소프트맥스 함수를 적용하여 총합이 1인 확률 분포를 도출함
- 어텐션 가중치(Attention Weight) : 각각의 값
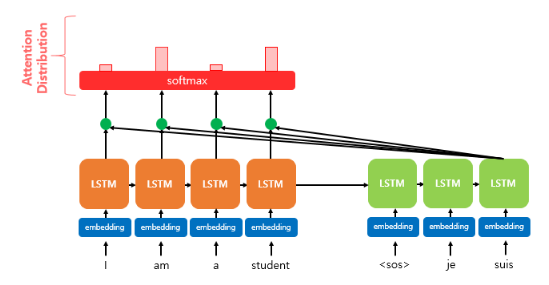
- 디코더의 시점 t에서의 어텐션 가중치의 모음값인 어텐션 분포
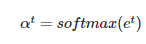
각 인코더의 은닉상태와 어텐션 가중치를 가중합 -> 어텐션값
- 아래 수식처럼 각 인코더의 은닉 상태와 어텐션 가중치값들을 곱하고, 모두 더함
ex)
어텐션 분포는 총합 1이기 때문에, 은닉상태가 3개 있다면 간단한 예로 어텐션 분포는 [0.96,0.2,0.2] 이런 값일 수 있다
이러한 값과 은닉상태를 곱해서 더해줌으로써, 은닉상태마다 가중치를 주는 효과를 준다.
예를 들어, 첫번째 은닉상태는 0.96의 가중치를 주게 된 상황이고, 두번째 은닉상태는 0.2의 가중치를 주게 된 상황이다
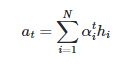
- a(t) : 어텐션 함수의 출력값, 어텐션 값
- 어텐션 값 a(t)는 인코더의 문맥을 포함하고 있음
-> 컨텍스트 벡터라고 불리기도함
-> 스칼라 값이 아님!
seq2seq의 컨텍스트 벡터는 인코더의 마지막 은닉상태
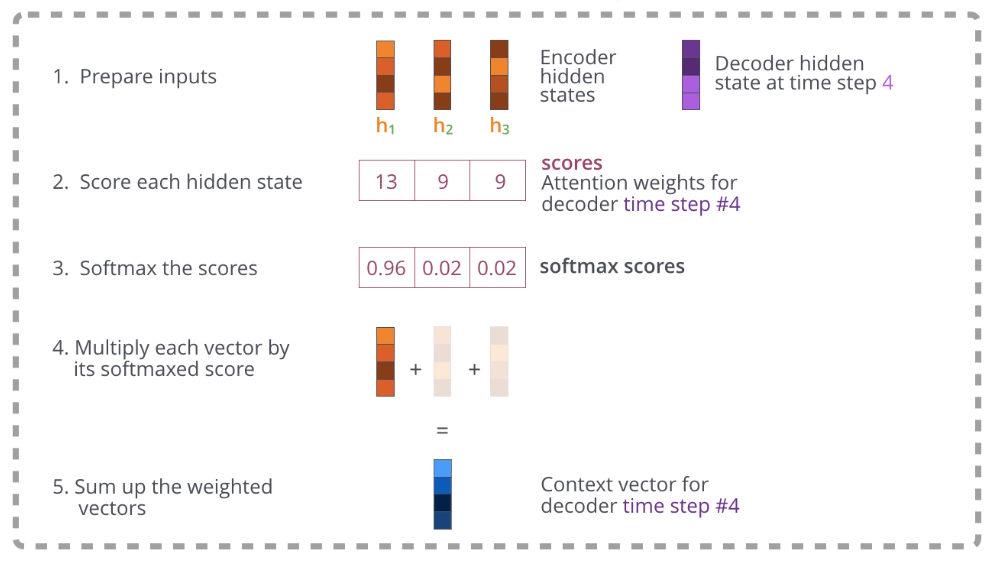
-> 이 그림을 보면 이해하기 쉽다!
3. 어텐션 값과 디코더의 t시점의 은닉상태를 연결
- a(t)와 s(t)를 결합(concatenate)하여 하나의 벡터로 만듦
- v(t) : 어텐션값과 디코더에서 예측하는 시점의 은닉상태(s(t))의 결합 벡터
"이 벡터를 연산의 입력으로 함께 사용함으로써 인코더로부터 얻은 정보를 활용하여 더 잘 예측 가능"
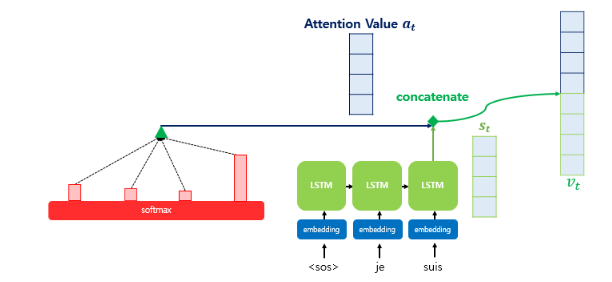
4. 출력
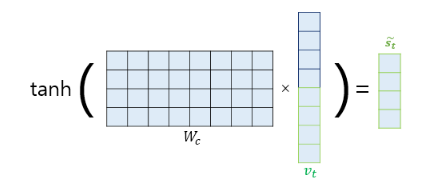
위 그림과 같이 v(t)에 가중치를 곱한뒤 tanh을 지나 출력층 연산을 위한 벡터 도출
기존 seq2seq에서는 출력층의 입력이 h(t) 였지만,
seq2seq attention에서는 출력층의 입력이 방금 도출한 벡터가 됨
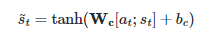
이후에 출력층의 입력으로 사용하는 과정은 아래 수식과 같다
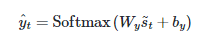
여기까지의 과정을 잘 나타낸 그림이 있어서 첨부한다
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
최근 10년 동안의 자연어 처리 연구 중에 가장 영향력이 컸던 3가지를 꼽는 서베이에서 여러 연구자들이 꼽았던 연구가 바로 2014년에 발표됐던 sequence-to-sequence (Seq2seq) + Attention 모델입니다 (Sutskev
nlpinkorean.github.io
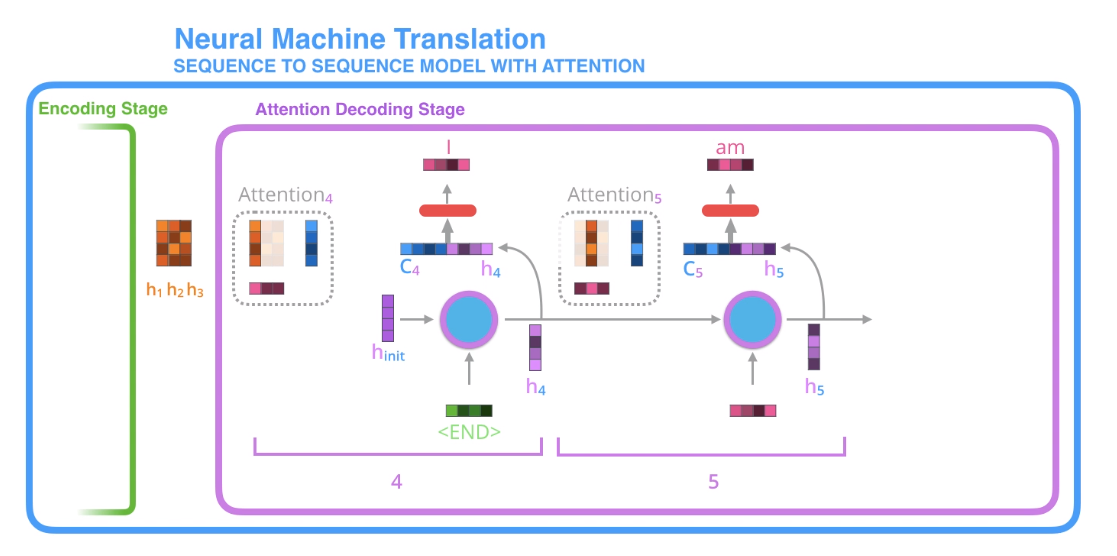
디코더의 첫번째 시점에서 I를 출력하게 되는 과정
1. 인코더의 마지막 시점 은닉상태가 넘어온다 (h.init)
2. h.init이 <END>와 함께 입력된다.
3. 입력을 바탕으로 디코더가 은닉상태 h4를 출력한다. -> 디코더의 첫번째 시점의 은닉상태
4. 인코더의 은닉상태 h1,h2,h3으로부터 어텐션을 통해 디코더의 첫번쨰 시점에 해당하는 벡터(C4)를 얻는다
- 핑크색 : 어텐션분포
- 핑크색 어텐션분포를 통해 h1,h2,h3에 가중치를 적용함 -> h1이 가장 중요한듯
- 얘네를 다 더한 것이 C4
5. C4와 h4를 연결하여 피드포워드 신경망, 활성화함수(tanh)를 지남
6. 최종 결과값은 디코더의 첫번째 시점에 해당하는 출력 단어를 나타냄
닷 프로덕트 어텐션은 어텐션 스코어를 구하는 방식이 내적이었기 때문에 그 이름이 붙었음
이 뿐만 아니라 다양한 방식의 어텐션이 있음
앞서 언급한 어텐션의 아이디어를 잘 기억하자
"디코더에서 출력 단어를 예측하는 매 시점마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고하자
단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 참고하자"
Attention : 유사도 응용의 끝판왕, 그리고 이건 언젠간 알아야 한다. (tistory.com)
Attention : 유사도 응용의 끝판왕, 그리고 이건 언젠간 알아야 한다.
혹시 신경망을 잘 모른다면 이 글은 나중에 읽었으면 좋겠습니다. 왜냐하면 이번 이야기는 신경망을 이용하는 이야기이기 때문에 지금까지 순서대로 착착 읽어 왔어도 이해하기 어려울 수 있습
recipesds.tistory.com
위 글에서 인용한 글귀
"query를 Decoder의 hidden state로, Key를 Encoder의 hidden states로 하면 Seq2Seq Attention"
"Query=Key=Value라면 self Attention"
이 두 개를 합하면 Transformer
'Python > NLP' 카테고리의 다른 글
| 트랜스포머(Transformer) - 인코더, 디코더 (0) | 2023.07.19 |
|---|---|
| 트랜스포머(Transformer) - 입력(포지셔널인코딩) (0) | 2023.07.15 |
| 시퀀스-투-시퀀스(seq2seq) (0) | 2023.04.11 |
| 장단기 메모리(Long Short-Term Memory, LSTM) (0) | 2023.03.26 |
| 워드투벡터(Word2Vec) (0) | 2023.03.20 |



